深度测评大模型
大模型深度测评
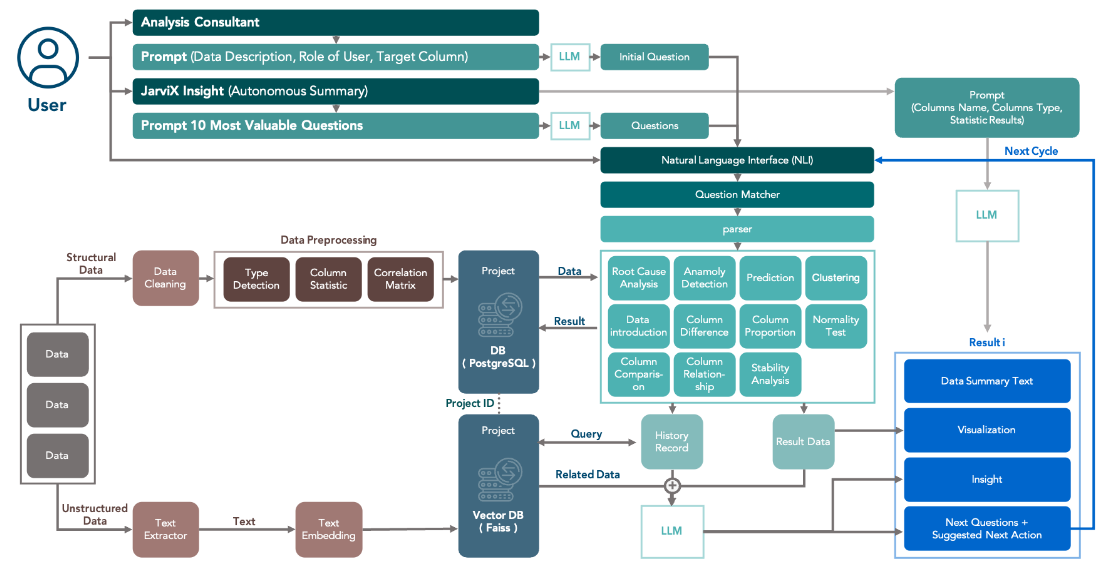
1、评价标准。测试数据集:
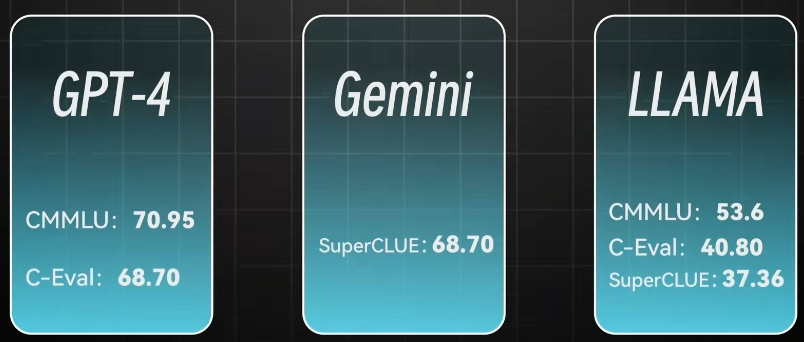
- MMLU:测试语言English、AI基础能力测试,美国教育体系下小学到本科57个学科知识,测试能力先验学习和解决问题。GPT4>ChatGLM4>Gemini Pro
- CMMLU:综合性中文评估基准,类似MMLU,主题包括国内九年义务教育到大学高等教育工67个主题,包括具有中国特定答案的任务(驾驶规则、社会基础法规)。BlueLM>通义>GPT-4
- C-EVAL:更广泛的综合性中文评估、包括注会、法考、公考、医师资格证等标准考试,中学到大学主流科目。BlueLM>MagecLM>MindGPT>通义千问
- superClUE:中文特点的评测基准,例如成语诗歌文学题材创作。GPT-4>文心一言>通义千问>OPPO AndesGPT
参考资料:
万字测评!18个主流大模型深度评测,读懂AI现状【深度模评03】

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 下雨天不打伞!
评论